Photo by Luke Chesser on Unsplash
Background
I began my first full-time role in June 2015. Since then, two technologies have consistently been part of my journey: Rails and Redis. Every company and project I have been involved with has utilized these technologies alongside others. In November 2015, Antirez (the author of Redis) wrote a blog post revealing a security vulnerability in Redis. This vulnerability allowed hackers to gain access to the machine where Redis was running through SSH if the Redis server was operating in non-protected mode (which was the default at that time) and the bind address was set to 0.0.0.0. The project I worked on was a website and host monitoring SaaS tool developed in 2010. At that time, creating a VPC was not mandatory, and all machines could run in a single flat network hierarchy called EC2-Classic (which AWS recently retired). This project also provided me the opportunity to move the entire system (from app servers to databases) inside the VPC by relaunching them gradually. The concepts I learned about VPC, networking, and security 8-9 years ago remain relevant today 😁.
Returning to the vulnerability — because we had a monitoring product that checked website uptime from different regions worldwide (similar to this), we had our website probing service running in various AWS regions and even on smaller cloud providers like Linode (Linode was a very simple and tiny cloud provider then). The application we ran was a small Ruby service with an attached Redis, deployed across multiple regions and providers. Back then, Docker and Kubernetes were not mainstream, and server setup was a mix of bash scripts and manual interventions. While our publicly exposed servers had basic SSH key authentication and services like fail2ban to handle repeat offenders, Redis was mostly running on default configuration, with the server bound to 0.0.0.0. This meant that someone could connect to Redis from outside if port 6379 (the default Redis port) was not protected through a firewall or security groups. As I mentioned, we were running this service on multiple cloud providers, which were not as feature-rich as AWS.
Many of our VMs running Redis were hacked, and this issue impacted numerous internet businesses in the following days. Fortunately, we resolved the issue by binding the machine to the localhost address (127.0.0.1), and a future upgrade of Redis enabled protected-mode by default. This was my first production encounter with a security breach that directly impacted our business because we lost access to those servers, and the feature stopped working. This taught me an important lesson - while default settings are acceptable for experimentation, they might not be suitable for running a production application.
In this blog post, I want to share my experience running Redis in production over the years. Although I haven’t managed a very complex Redis infrastructure, these experiences should still benefit those who operate databases or are generally interested in learning about them.
What is Redis?
Before using Redis, I was only familiar with SQL databases, so Redis seemed very different. I referred to it as a “data-structures db” because it implemented many commonly used data structures like lists, hashes, sets, etc. In all the codebases I’ve reviewed, the most common use case for Redis is as a key-value store (essentially string-based GET, SET). However, Redis supports many more features beyond this:
-
SET allows the EX parameter to set expiring keys, a very useful feature for cache invalidation.
-
SET also allows the NX parameter to set the key only if it doesn’t exist. SET with the XX parameter does the opposite. At the application layer, libraries return a boolean value to indicate if the key was set or not. This is very useful for implementing distributed locks. In fact, Redis is very popular for implementing distributed locking.
-
The List data structure in Redis allows pushing and popping from both the left and right sides, making it useful as both a stack and a queue. In fact, the most popular background job libraries for Python and Ruby use Redis lists for queuing.
-
Redis also supports Geospatial calculations. A use case for this could be storing map locations of multiple fuel stations in your area and then using Redis commands to determine which one is closest to your location. Or perhaps list all the fuel stations in ascending order of their distance, within 3 km. Isn’t that cool?
-
Redis also supports PubSub and Streaming. PubSub enables real-time, fire-and-forget message broadcasting, making it perfect for instant updates like chat messages or live stock prices where no history is needed. In contrast, Streams provide a durable, replayable event log with consumer groups, ideal for processing workflows or pipelines that need message persistence and ordered delivery.
-
Redis also supports approximate data structures like Bloom filters, HyperLogLogs and has support even for TimeSeries data.
While the most common usages are for String, List, and Hash data structures, Redis supports a wide range of other features out of the box. If you’re new to Redis or not familiar with these features, I recommend trying them on your local machine.
Use cases solved
At it’s core, Redis is a NoSQL database that supports lots of data structures and also solves for many other use cases like streaming, time series data sampling, geospatial computation, etc. In this section, we’ll explore more about Redis use cases for providing standard solutions to common problems:
-
Caching - If you’re using Redis in production, there’s a high likelihood you’re using it for caching. Developers love Redis for caching due to its in-memory nature, which helps improve service response times and reduce load on SQL databases.
-
Queueing - As previously explained, Redis is widely used as a queue to solve the problem of distributed background processing. You don’t need to write anything beyond business logic, as the problem is common and already solved by libraries in your preferred language using Redis as a queue.
-
Rate limiting - Building a Rate Limiter is a common problem, especially when exposing APIs to the public. There are multiple algorithms to implement a Rate Limiter that can be built over Redis using its supported data structures.
-
Distributed locking - If you’re from a SQL background, you might have used Row locks (like
SELECT FOR UPDATEin Postgres) for similar purposes. However, many times you’ll have use cases to lock something not yet persisted in a SQL database. Redis locks are handy in those cases.
Enough of selling Redis, let’s discuss some learnings.
Learnings and Recommendations
Do I need the multiple Redices?
I’ve seen applications grow from a few thousand users to millions. In a simple stack, we usually start with one Redis instance. As the product grows, more developers realize use cases for Redis and continue building on top of it. However, there are instances when you should consider adding a second Redis machine to your infrastructure:
-
Sharing across services - As with any other database, we should avoid sharing a Redis machine across different services. A Redis instance shouldn’t be considered as a dump-all cache for multiple services. The primary reason for this is the single point of failure, and no one would want that kind of setup.
-
Having different use cases - In a previous organization, we had an application with four Redis instances connected to it. Each had a different use case and its own configuration. Separating databases based on use cases helps in tuning and managing them separately. Some people might not do this initially and later realize that separating them initially was a good idea.
-
Separating cache vs. persisted storage - This is a special case of previous point (different use cases). Sometimes it’s still ok to not separate Redices for use cases because they’re small enough but it’s never okay to combine use case of cache vs persisted storage. Most of the people put Redis in a place where flushing it doesn’t impact anything (apart from some intermittent CPU peaks in the primary database) because the data can be repopulated. But there are some use cases where you can’t afford to drop database because Redis is the primary database. One very good example for this is when you use Redis as a database for background job processing (example1, example2). In such cases, you cannot afford to lose jobs even if the Redis process crashes, making it important to run Redis in persisted mode. Depending on your Redis version and current configuration, you might need to tune it for your persistence use case, balancing durability and performance.
Based on use cases, persistence, latency, and other tuning requirements, you might want to separate Redis early on to avoid migration overhead.
Using expiring keys
I’ve seen apps where the count of keys easily grows beyond 10 million. It’s not bad to have this many keys as long as you have the memory available, but in some cases, it might not be justified given the app size and use cases. A primary reason for ever-growing keys in Redis is not setting expiry for keys. On analyzing key patterns on various Redis machines, I’ve often come across keys for which the corresponding application code was deleted long ago, but the developers didn’t clean up the respective keys. As Redis is an in-memory database, useless keys mean wasted RAM. I’m not saying all keys should be expiring, but if you’re considering running in cache mode, your application code should manage repopulating Redis as needed. Some good examples of expiring keys are:
-
When Redis is used for distributed locking, we can set an expiry on the lock key. This TTL is generally higher (or a few times) than the task execution time. This ensures that if the application logic fails to clean up the lock key, it gets automatically cleaned up, avoiding infinite locking.
-
We often use Redis for storing temporary passwords and OTPs, and in most product specifications, there is an expiry associated with this OTP. Setting TTL on such keys helps build this feature without additional application logic.
If you see your Redis memory graph in an ‘ever-increasing trend”, it might be a good time to revisit if you really need all those keys 😁.
Caching invalidation & application hooks
There are only two hard things in Computer Science: cache invalidation and naming things.
-- Phil Karlton
Although this is not directly related to Redis, I often see the problem of cache invalidation discussed among people who use Redis for caching. So I thought of sharing a few best practices. Caching is a powerful technique for improving application performance, but it comes with the challenge of cache invalidation. Properly managing cache invalidation is crucial to ensure your application serves accurate data. Here are some key points to consider when setting up cache invalidation hooks:
-
Understand the Data Lifecycle: Before setting up cache invalidation, it’s important to understand the lifecycle of the data being cached. Identify when data changes and how those changes should be reflected in the cache. I’ve often seen people caching the response of an entire API to save time in querying and serialization. This is good if the API is Restful, but if it queries multiple data sources to generate that response, there might be multiple hooks on which you need to reset the cache. So take care of such edge cases.
-
Suitable Hooks for Invalidation: We should update the cache once the data in primary data source has been updated. For a Rails application, we use
after_commithook for the respective model to update the respective cache. I asked ChatGPT for parallels in other languages/frameworks and got this for your reference 😁
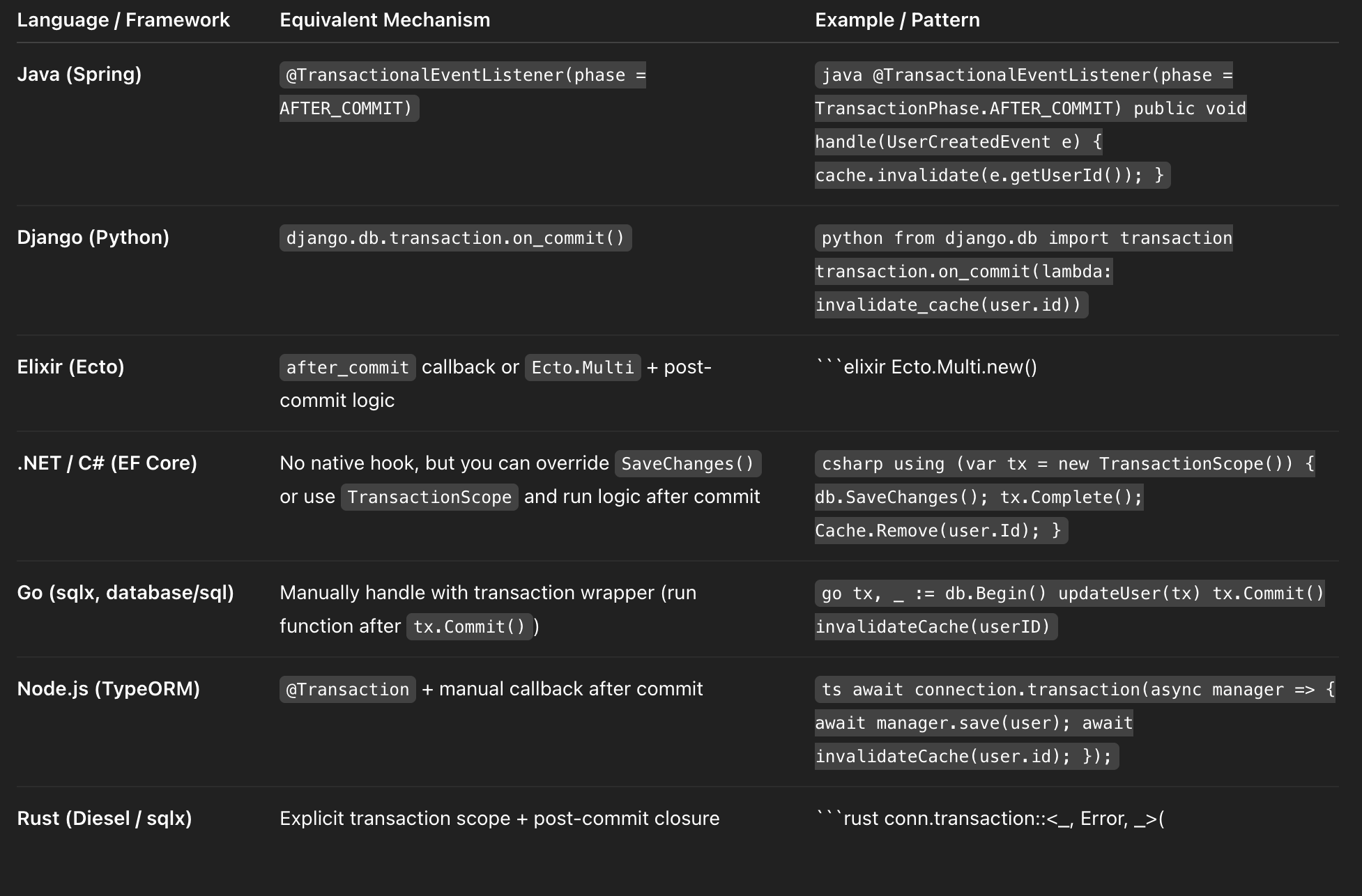
-
Set Expiry Times: ome people use expiry times as a band-aid for cache invalidation. This could be to defer the fix for the actual bug in some cases (e.g., when you don’t know all the hooks to invalidate the cache). A similar case where we used such expiring keys in the past was to update feature rollouts for a user. To see enabled features for a user, we earlier relied on a SQL-backed system that performed checks on at least four levels before telling if the feature is enabled on the user or not. But as the system grew in complexity and we added an authorization layer, such checks became more widespread. The query to check enabled features got flagged as one of the most used queries in our APM tool, and we fixed this in two phases: In the first phase, we cached this data for 5 minutes and ensured that we don’t query from the SQL database within these 5 minutes. While this might not be acceptable in many use cases, it was okay for this use case as the latency of 5 minutes for turning a feature on/off was acceptable to product and business teams. As we got some breathing space, we figured out all the hooks in the different models to invalidate this cache. We could have completely removed the TTL, but we rather set it to a higher value (e.g., 7 days) to ensure that we don’t cache data for users who don’t come to our app often.
-
Use Versioning: Implementing versioning for cache keys can help manage cache invalidation. By appending a version number to cache keys, you can easily invalidate old entries by incrementing the version number when data changes. For systems where we have timestamps like
updated_at, developers often use that as a versioning key because it naturally tracks an update in the system.
By carefully setting up cache invalidation hooks and strategies, you can maintain the integrity of your application’s data while leveraging the performance benefits of caching.
Tuning the configuration
This is true for all databases, not just Redis. Whenever you’re planning to run anything in production, it’s good to know about various parameters that you can tune. For ages, we’ve been operating single-node centralized databases that persist data on disk, and they generally run fine with default settings unless you hit some metric (IO/CPU/RAM) really hard. But the same is not true for distributed NoSQL databases. Based on the configuration, such databases can be tuned to compromise consistency or availability for speed, scalability, and fault tolerance.
All databases have at least one configuration file available to tune different parameters for your use case. There are sufficient comments in the file for documentation purposes (although their websites have more detailed explanations, if needed). You can access these files to tune the database only if you’re self-managing the database installation on a virtual machine like AWS EC2. If you’re using managed services like AWS RDS, AWS Elasticache, etc., then you’d be exposed to a limited set of parameters through their GUI (like Parameter Groups in AWS).
To see a sample Redis conf, you can check this link or google “redis stable conf” . I’ll talk about a few useful config parameters for Redis:
-
Persistence: Redis, by design, is an in-memory data store, which makes it extremely fast but raises an important question — what happens to your data when the process crashes or the machine restarts? To handle this, Redis supports multiple persistence mechanisms that balance speed, durability, and operational overhead differently. Broadly, Redis offers two major forms of persistence: RDB (snapshotting) and AOF (append-only file). The RDB persistence mechanism takes point-in-time snapshots of your dataset and writes them to disk as a
.rdbfile. Redis forks a background process (also called as BGSAVE or background save) to perform the dump, ensuring the main process remains responsive. It reads yoursaveconfiguration from theredis.confto decide when it should run the background save process. I’ll explain this with an example ofsaveparameter.save 900 1 save 300 10 save 60 10000This configuration means: save after 1 change within 15 minutes, or save after 10 changes within 5 minutes, or save after 10,000 changes within 60 seconds. These rules can be customized or even disabled with
save ""for a super-fast cache-like setup. The other setup is AOF where Redis provides finer-grained durability than RDB by logging every write operation Redis performs. On restart, Redis replays the AOF log to rebuild the in-memory dataset. The two important parameters here are:appendonly(should be set toyesto use this mode) andappendfsync. The second property defines how frequently you flush to the disk (possible values:no,everysec,always). In most production environments,appendonly everysecis a safe balance — ensuring sub-second durability without blocking throughput. For extremely fast ephemeral caches,appendonly nocan be used for maximum performance. If you set this property toalways, Redis will enter into fully durable mode. This means — every time Redis executes a write command (e.g.SET,LPUSH,INCR), it appends that command to the Append-Only File (AOF) on disk, and then calls thefsync()system call immediately afterward — before acknowledging success to the client. This guarantees that even if the OS or machine crashes immediately after acknowledgment, the data is physically on disk and recoverable.Note on fsync:
fsyncis a system call that ensures all pending writes for a given file descriptor are flushed from the kernel’s page cache to the physical storage device. By default, when you callwrite(), the data goes into the kernel’s buffer cache, not immediately to disk — the OS decides when to flush it.fsync()forces that flush right now and waits until the device confirms that data is persisted. -
Databses - There’s a controversial feature inside Redis. Redis by default supports 16 databases (numbered 0 to 15) which we can choose using the SELECT command. I’ve not used this in many projects but in of the use-cases, this feature helped me separate data into different namespaces. I was talking to someone few months ago and they mentioned that this feature is considered as an anti-pattern. To understand a bit more, I did some research and found why some people don’t like this feature:
-
Redis cluster mode doesn’t support databases because of implementation complexity. So it’s supported only if you’re running a single node Redis (with/without replicas).
-
All DBs share same memory, persistence, and config. So there’s no isolation in the way data is stored in memory or on disk. This also means that the configuration we chose for the server applies to all the databases.
-
There are commands like
FLUSHDBto flush one database (the one you’re currently on), but there’s also aFLUSHALLcommand that wipes all databases, easy to cause total data loss by mistake. -
As the backup files (RDB or AOF) contains all the databases together, you cannot selectively restore one of them in event of crash or restart. You need to wait for the entire file dump to load in memory.
-
Like I used it — there were slightly different use cases in my project so I thought it’s better to separate the namespace but this could easily create the noisy neighbour problem and the monitoring tools can hardly differentiate between metrics based on database number.
Due to all these reasons, even the creator of Redis recommends using different Redis instances rather than using different database numbers.
-
-
Replication - Redis supports asynchronous replication with extensive tunable parameters, but achieving reliability requires balancing latency, durability, and consistency:
-
Replication is asynchronous by default, meaning replicas may lag or lose writes if the primary crashes before sync.
-
Use
repl-diskless-sync yesfor faster initial syncs and reduced I/O overhead; otherwise, RDB-based syncs (repl-diskless-sync no) can block during snapshot creation. -
Tune
repl-backlog-sizeandrepl-backlog-ttlto maintain replication continuity across brief disconnects — preventing full resyncs. -
Enable
min-replicas-to-writeandmin-replicas-max-lagto protect against acknowledging writes when replicas are stale or disconnected. -
Always monitor replication lag via
INFO replication— even small lags can break consistency assumptions in queue or locking workloads.
-
-
Memory management - By carefully managing memory settings, you can ensure that Redis operates efficiently and reliably, whether used as a cache or for persistent storage.
-
When using as a cache, it is useful to configure parameters like
maxmemoryandmaxmemory-policyto evict data based on algorithms like LRU, LFU, etc. If there are no keys that match the criteria for eviction and maximum memory is reached, Redis will report errors for write commands. -
When using for persistent storage, you should set
maxmemory-policytonoevictionand leave 30-40% free memory. This buffer protects against fragmentation, background save forks, and transient spikes ensuring Redis never evicts queued jobs or stalls under memory pressure.
-
-
Tuning Data structures performance - There are certain parameters that influence how Redis internally represents its core data structures. Tuning them can significantly impact memory efficiency and CPU performance. Let’s understand these for a few data structures:
-
Hashes
-
hash-max-listpack-entries 512 -
hash-max-listpack-value 64
Redis stores small hashes in a compact, contiguous area for better cache locality. Once a hash exceeds either threshold (more than 512 fields or a field value longer than 64 bytes), Redis automatically converts it into a standard hash table. Increase these limits for smaller hashes to save memory; decrease if you have frequent large-field updates to avoid costly re-encodings. Instagram optimised this parameter for their use case back in 2011 (read more).
-
-
Lists
-
list-max-listpack-size -2 -
list-compress-depth 0
Small lists are also stored as flat contiguous memory.
list-max-listpack-sizecontrols the maximum size of each listpack node;-2means Redis targets listpack nodes of roughly 8 KB.list-compress-depthdefines how many nodes at the list’s ends remain uncompressed —0disables compression entirely. For read-heavy queues, keep compression low (0–1) for fast access. For archival or long lists, allow deeper compression (2–3) to save memory. -
-
Sets
-
set-max-intset-entries 512 -
set-max-listpack-entries 128 -
set-max-listpack-value 64
Redis represents small sets of integers as intsets, and small generic sets as listpacks. Once a set exceeds these thresholds (by count or member size), it upgrades to a full hash table internally. Increase thresholds for workloads with many small sets to reduce overhead. Lower thresholds if set membership changes frequently to avoid repeated re-encodings.
-
Note: I’ve heard of these configurations many times but never got a chance to optimise Redis for these use cases. Although these look like advanced configuration, these could be useful for you if your use-case revolve around specific data structures only and you’re running on a huge scale, it might be worth experimenting with these settings. Also, before playing around with configurations for any data structure, have a good idea about what all data structures you are using in your application. For example, Redis implements Geospatial data structures internally using sorted set (ZSET). So if you change configuration for
zset-max-listpack-entriesorzset-max-listpack-valueit would also impact the performance and storage for Geospatial keys (incase you’re using those). -
Beyond these, Redis exposes several other configuration parameters that impact
-
Security (eg.
bind,protected-mode,requirepass,masterauth) -
Define clustering (for sharding data across nodes)
-
Performance (
timeout,tcp-keepalive,latency-monitor-threshold) -
Maintainability (
maxclients,loglevel,rename-command), etc.
Redis is single-threaded (wait… what?)
Redis is famously known as a single-threaded data store — a design choice that often raises eyebrows among developers used to multi-threaded applications and databases. The assumption is natural: single-threaded means slow, right? In this case, the answer is “no — not really.” When Redis is called single-threaded, it means that only the core command execution loop is one single thread. All commands are executed sequentially, one after another. Each incoming request is parsed, executed, and responded to before moving to the next one — with no context switches or locking. This design avoids the biggest enemy of high-performance systems: concurrency overhead.
Despite being single-threaded, Redis is capable of handling hundreds of thousands of operations per second on a single core. Here’s why:
-
Redis stores all data in RAM so there’s no disk I/O during command execution. Each operation typically completes in microseconds.
-
Since there’s only one command executor, there’s no need for fine-grained locking, atomic sections, or concurrency control — all commands are inherently atomic (hence safe for distributed locks).
-
Redis multiplexes I/O events in a single loop (similar to Node.js). This means one thread can serve thousands of connections efficiently.
-
Redis batches replies and writes them efficiently, minimizing expensive kernel transitions.
-
Operations like background save fork a child process does not impact the command execution directly (“indirect” impact is explained below).
Redis proves that single-threaded doesn’t mean slow — when data lives in memory, network latency and locking costs matter more than CPU parallelism. Its design trades concurrency for deterministic speed, making it one of the fastest databases per core ever built. But there are some cases where command execution can be impacted:
-
Redis supports Lua scripting but those are executed within same single-threaded event loop. So large/complicated lua scripts can slow down this thread.
-
Commands with high time complexity can slow down this event loop. For example: If you’re running
LRANGEon a large list orSMEMBERSon a large set, it might take time to execute them and any commands that are fired afterwards. Redis official documentation mentions time complexity of all the commands. -
DELcommand can be slow if you’re trying to free up large memory blocks synchronously.UNLINKcan be used in those situations. -
There’s a very popular and notorious command in Redis called
KEYS. I took a production Redis down for a few seconds during my first encounter with Redis 😛. Because this iterates the entire keyspace and production systems (generally) have millions of keys, this command takes a lot of time to execute. -
Background save for large data sets (>10GB as per ChatGPT) can have some intermittent impact on the command execution thread.
Safely analyzing data with KEYS command
There are multiple ways for doing this:
-
First method is to avoid this as much as possible. Revisit your use case and check for alternate methods.
-
Redis documentation would recommend using
SCANinstead ofKEYSand use of the pointer (cursor) returned with each output to get next set of keys but you would need some application level logic to follow the cursor iteratively and filter keys by names incase you’re searching for some specific pattern of keys (eg. keys starting with wordalert). For this specific purpose, I’ve tried a workaround:-
Setup a replica of this Redis.
-
Disconnect the replica from MASTER (command:
REPLICAOF NO ONE). -
Ensure there are no connections to this replica now, except your current session (use
CLIENT LISTto see connected clients andMONITORto see if someone is running any other command). -
Now run
KEYS *here so that there’s no impact elsewhere.
-
If your purpose is doing some analytics, somewhat old data might not cause any problems.
How I saved 75% cost due to single core usage
By now, we know two things about Redis:
-
It’s uses a single CPU Core.
-
It’s an in-memory database. So for production machines, you need boxes with large amount of RAM.
In one of my prev organisations, we had four Redis machines connected to a monolith application:
-
One was for background queueing (full persistence needed, can’t lose data).
-
One was for some alert thresholds (persistence needed).
-
One was a pure cache use case (speed preferred)
-
One was for acting as a database for a high performance system (using lists/sets mostly) (persistence needed).
Out of these, three were hosted on VMs (AWS EC2) and one on managed service (AWS Elasticache). The organisation was trying to cut costs from all sides and our own production infra was a significant component of that cost. After cutting all corners, we saw another opportunity — we could merge these Redices into one big EC2 machine. For some, this might sound like a stupid decision because it would mean a single point of failure for the application (i.e. if this EC2 goes down, everything goes down). But we still did moved ahead to this setup because cost cutting were our only targets.
We took a machine with 4 cores, ran four Redis processes on different ports and exported data from existing machines, saving 75% on Redis costs. One learning that I got in this process is — you can’t create replica of a Elasticache Redis outside Elasticache ecosystem (basically EC2 cannot act as replica of Elasticache hosted Redis). So in order to copy data, we had to export it to S3 and copy that backup file on the new machine which increased our migration downtime by a few minutes.
Deployment options and Cloud providers
Redis can be deployed in several topologies, each balancing availability, consistency, and operational complexity differently. From a single instance to fully distributed clusters, the choice depends on whether your priority is simplicity, high availability, or scalability. I have mostly operated first two setups but I’ll share four of them for your reference:
-
Standalone: A single Redis instance handling all reads and writes. It is simple, fast, and ideal for development environments or small production caches with no fault tolerance if it goes down.
-
Master–Replica: A primary node manages writes while replicas asynchronously copy data for read scalability and redundancy, offering better availability but manual recovery on failure.
-
Sentinel: A lightweight layer that monitors master–replica setups, automatically promotes replicas during failures and updates clients, bringing high availability without clustering.
-
Cluster: A distributed Redis setup that shards data across multiple masters with replicas for each, enabling horizontal scalability and built-in failover for large, production-scale workloads.
Beyond this, I also wanted to touch upon an important thing that is kind of deployment - self managed vs. provider managed. For provider managed Redis services (eg. AWS ElastiCache, Azure Cache or GCP Memorystore), the provider takes care of the heavy lifting from provisioning to scaling, failover, patching, and monitoring, making them production-ready but that convenience comes with trade-offs in control and flexibility. Some reasons are:
-
Limited configuration control - You can only modify parameters exposed via their UI (eg. parameter groups). Many performance and persistence knobs remain locked. One reason for this is that Redis license has changed multiple times since 2021 and the newer one doesn’t let the cloud provider run the original Redis as a managed service. So all of them fork Redis 6.x (till which license was relaxed) and maintain their own implementation. Because the API layer and protocol is compatible with the original Redis, developers hardly care about this fact.
-
Restricted operational access - Direct shell access (
redis-cli,INFO allwith full privileges) is limited or read-only. You can’t inspect/var/log/redisor the underlying OS, so debugging memory fragmentation, CPU throttling, or swap usage becomes harder. -
Limited control during freezes or failovers - If a node hangs (e.g., fork stall, full memory pressure), you can’t SSH or restart the process. You must wait for the cloud provider’s control plane to detect failure and trigger replacement — which can take minutes. For production use cases, this can cause serious damage by the time this gets fixed. It did much damage for one of the teams I worked with, and they started hating Redis because of this.
-
Version lag and feature delays - Managed offerings usually trail open-source Redis by a few releases. New features (e.g., active-active replication, ACL improvements, new data encodings) arrive late or in enterprise-only tiers.
-
Higher cost for flexibility - While managed Redis saves operational effort, it’s significantly more expensive per GB of memory. Running Redis on self-managed EC2 is often 50% cheaper.
Popularity and alternatives
For over a decade, Redis has been the standard choice for in-memory data store because of its speed, simplicity, and versatility. As of 2025:
-
Redis continues to rank among the top 10 databases on the DB-Engines index, often #1 in the key-value category.
-
Major companies rely on it for both caching and primary storage of ephemeral workloads.
-
Virtually every cloud platform offers Redis (or compatible software) as a first-class managed service.
While providers with managed Redis services have different forks of Redis due to license reasons, there have been parallel initiatives by many open source and closed source teams leading to softwares which are 100% API compatible with Redis. To name a few:
-
AWS Memory DB is a durable, in-memory, Redis-compatible database service that delivers ultra-fast performance with multi-AZ durability. MemoryDB stores all data in memory for sub-millisecond reads, but persists every write to a distributed transactional log (across multiple AZs in AWS). If the cluster or all nodes crash, MemoryDB can rebuild the in-memory state from that log — unlike ElastiCache, which would rely on periodic snapshots.
-
Garnet is a research project by Microsoft Research. It uses the RESP wire protocol, making it compatible with standard Redis clients in many languages but unlike Redis’s single-thread command execution, Garnet’s storage layer is designed to scale across threads within a node. It can work over memory, SSD, and even remote storage (e.g., Azure storage) to support datasets larger than memory.
-
DiceDB is an open-source, in-memory, reactive database written in Go. It is Redis protocol compatible while adding features like subscriptions / query reactivity (push updates rather than polling). It is designed to better utilize multi-core hardware rather than being stuck with a single-threaded event loop. I was following the creator of this project for a while, who had created this mostly for learning purposes and had not tested this on large number of production applications yet.
-
DragonflyDB is a high-performance drop-in Redis replacement written in C++. It is fully API-compatible with Redis, supports multi-threaded execution, and often 2–3× faster in mixed workloads. It uses lock-free structures and shared-nothing architecture, avoiding Redis’s single-thread bottleneck. It is known to be extremely efficient with memory and CPU — ideal for modern multi-core servers.
Debugging performance bottlenecks
To ensure optimal performance of Redis in production, it’s essential to monitor and debug performance bottlenecks effectively. Here’s a concise guide:
-
INFO Command: The
INFOcommand in Redis is a versatile tool that provides a comprehensive overview of the server’s status and performance metrics. When executed, it returns a wealth of information categorized into sections such as server, clients, memory, persistence, stats, replication, CPU, and keyspace. This command is invaluable for monitoring and diagnosing the health of your Redis instance. For latency analysis, theINFOcommand can help identify potential issues by providing insights into metrics like the number of connected clients, memory usage, and command statistics. High memory usage or a large number of connected clients can contribute to increased latency, and theINFOcommand helps pinpoint these areas. -
Slow logs: They are essential for identifying performance bottlenecks by tracking commands that exceed a specified execution time threshold. Configured through parameters like
slowlog-log-slower-thanandslowlog-max-len, slow logs capture detailed entries of long-running commands, including their execution time and timestamp. By analyzing these entries, you can pinpoint specific commands or patterns causing delays, guiding you in optimizing command performance or adjusting Redis configurations. I’ve used this a few times to figure out usage of some commands on large data structures causing slowness in command execution thread. -
Latency Doctor: Utilize the
LATENCY DOCTORcommand to analyze and report on latency spikes, providing insights into potential causes. When you run theLATENCY DOCTORcommand, Redis examines its internal latency history and generates a report. This report includes details about various latency events, such as their frequency and potential causes. The command analyzes different aspects of the server’s operation, including command execution, memory management, and I/O operations. Based on the insights provided byLATENCY DOCTOR, you can take specific actions to mitigate latency issues. -
Connection Pooling: Always implement connection pooling on the client side to manage Redis connections efficiently. This reduces the overhead of establishing new connections by reusing existing ones, which most client libraries support.
-
Monitoring Tools: Employ monitoring tools that can instrument Redis metrics, such as Datadog, New Relic, or AWS CloudWatch. Key metrics to monitor include:
-
Memory Usage: Track used and peak memory to prevent out-of-memory errors.
-
Command Latency: Monitor the time taken to execute commands to identify slow operations.
-
Keyspace Hits/Misses: Analyze cache efficiency by observing the ratio of hits to misses.
-
Evicted Keys: Keep an eye on the number of keys evicted due to memory limits, which can indicate the need for configuration adjustments.
-
By using these strategies and tools, you can effectively monitor and address performance bottlenecks in your Redis environment.
Closing note
Reflecting on my journey with Redis over the years, it’s clear that this powerful tool has been more than just a component in my tech stack; it’s been a constant companion. From my early days of grappling with security vulnerabilities to tweaking the nuances of Redis configurations, each experience has enriched my understanding and appreciation of this versatile database.
As I share these insights, my hope is that they resonate with you, whether you’re just starting out or are well-versed in the world of Redis. Remember, while technical knowledge is crucial, it’s the personal experiences and challenges overcome that truly shape our expertise. Here’s to embracing the learning curve and continuing to explore the endless possibilities that such databases offer. Thank you for sparing time to read this.
If you liked this post, you might also like these:
-
Having worked with small teams mostly, I’ve been a proponent of keeping the tech stack very simple. I shared my thoughts around the same.
-
I wrote a post early this year about habits, productivity and deep work.
-
If you’re transitioning from monolith to microservices and are looking for a scalable way to migrate data, read this post once.